Architecture and Requirment
Terminology
| Term | Description |
|---|---|
| User | A single data-scientist/data-engineer. User has resource quota, credentials |
| Team | User belongs to one or more teams, teams have ACLs for artifacts sharing such as notebook content, model, etc. |
| Admin | Also called SRE, who manages user's quotas, credentials, team, and other components. |
Background
Everybody talks about machine learning today, and lots of companies are trying to leverage machine learning to push the business to the next level. Nowadays, as more and more developers, infrastructure software companies coming to this field, machine learning becomes more and more achievable.
In the last decade, the software industry has built many open source tools for machine learning to solve the pain points:
It was not easy to build machine learning algorithms manually, such as logistic regression, GBDT, and many other algorithms: Answer to that: Industries have open sourced many algorithm libraries, tools, and even pre-trained models so that data scientists can directly reuse these building blocks to hook up to their data without knowing intricate details inside these algorithms and models.
It was not easy to achieve "WYSIWYG, what you see is what you get" from IDEs: not easy to get output, visualization, troubleshooting experiences at the same place. Answer to that: Notebooks concept was added to this picture, notebook brought the experiences of interactive coding, sharing, visualization, debugging under the same user interface. There're popular open-source notebooks like Apache Zeppelin/Jupyter.
It was not easy to manage dependencies: ML applications can run on one machine is hard to deploy on another machine because it has lots of libraries dependencies. Answer to that: Containerization becomes popular and a standard to packaging dependencies to make it easier to "build once, run anywhere".
Fragmented tools, libraries were hard for ML engineers to learn. Experiences learned in one company are not naturally migratable to another company. Answer to that: A few dominant open-source frameworks reduced the overhead of learning too many different frameworks, concepts. Data-scientist can learn a few libraries such as Tensorflow/PyTorch, and a few high-level wrappers like Keras will be able to create your machine learning application from other open-source building blocks.
Similarly, models built by one library (such as libsvm) were hard to be integrated into machine learning pipeline since there's no standard format. Answer to that: Industry has built successful open-source standard machine learning frameworks such as Tensorflow/PyTorch/Keras so their format can be easily shared across. And efforts to build an even more general model format such as ONNX.
It was hard to build a data pipeline that flows/transform data from a raw data source to whatever required by ML applications. Answer to that: Open source big data industry plays an important role in providing, simplify, unify processes and building blocks for data flows, transformations, etc.
The machine learning industry is moving on the right track to solve major roadblocks. So what are the pain points now for companies which have machine learning needs? What can we help here? To answer this question, let's look at machine learning workflow first.
Machine Learning Workflows & Pain points
1) From different data sources such as edge, clickstream, logs, etc.
=> Land to data lakes
2) From data lake, data transformation:
=> Data transformations: Cleanup, remove invalid rows/columns,
select columns, sampling, split train/test
data-set, join table, etc.
=> Data prepared for training.
3) From prepared data:
=> Training, model hyper-parameter tuning, cross-validation, etc.
=> Models saved to storage.
4) From saved models:
=> Model assurance, deployment, A/B testing, etc.
=> Model deployed for online serving or offline scoring.
Typically data scientists responsible for item 2)-4), 1) typically handled by a different team (called Data Engineering team in many companies, some Data Engineering team also responsible for part of data transformation)
Pain #1 Complex workflow/steps from raw data to model, different tools needed by different steps, hard to make changes to workflow, and not error-proof
It is a complex workflow from raw data to usable models, after talking to many different data scientists, we have learned that a typical procedure to train a new model and push to production can take months to 1-2 years.
It is also a wide skill set required by this workflow. For example, data transformation needs tools like Spark/Hive for large scale and tools like Pandas for a small scale. And model training needs to be switched between XGBoost, Tensorflow, Keras, PyTorch. Building a data pipeline requires Apache Airflow or Oozie.
Yes, there are great, standardized open-source tools built for many of such purposes. But how about changes need to be made for a particular part of the data pipeline? How about adding a few columns to the training data for experiments? How about training models, and push models to validation, A/B testing before rolling to production? All these steps need jumping between different tools, UIs, and very hard to make changes, and it is not error-proof during these procedures.
Pain #2 Dependencies of underlying resource management platform
To make jobs/services required by a machine learning platform to be able to run, we need an underlying resource management platform. There're some choices of resource management platform, and they have distinct advantages and disadvantages.
For example, there're many machine learning platform built on top of K8s. It is relatively easy to get a K8s from a cloud vendor, easy to orchestrate machine learning required services/daemons run on K8s. However, K8s doesn't offer good support jobs like Spark/Flink/Hive. So if your company has Spark/Flink/Hive running on YARN, there're gaps and a significant amount of work to move required jobs from YARN to K8s. Maintaining a separate K8s cluster is also overhead to Hadoop-based data infrastructure.
Similarly, if your company's data pipelines are mostly built on top of cloud resources and SaaS offerings, asking you to install a separate YARN cluster to run a new machine learning platform doesn't make a lot of sense.
Pain #3 Data scientist are forced to interact with lower-level platform components
In addition to the above pain, we do see Data Scientists are forced to learn underlying platform knowledge to be able to build a real-world machine learning workflow.
For most of the data scientists we talked with, they're experts of ML algorithms/libraries, feature engineering, etc. They're also most familiar with Python, R, and some of them understand Spark, Hive, etc.
If they're asked to do interactions with lower-level components like fine-tuning a Spark job's performance; or troubleshooting job failed to launch because of resource constraints; or write a K8s/YARN job spec and mount volumes, set networks properly. They will scratch their heads and typically cannot perform these operations efficiently.
Pain #4 Comply with data security/governance requirements
TODO: Add more details.
Pain #5 No good way to reduce routine ML code development
After the data is prepared, the data scientist needs to do several routine tasks to build the ML pipeline. To get a sense of the existing the data set, it usually needs a split of the data set, the statistics of data set. These tasks have a common duplicate part of code, which reduces the efficiency of data scientists.
An abstraction layer/framework to help the developer to boost ML pipeline development could be valuable. It's better than the developer only needs to fill callback function to focus on their key logic.
Submarine
Overview
A little bit history
Initially, Submarine is built to solve problems of running deep learning jobs like Tensorflow/PyTorch on Apache Hadoop YARN, allows admin to monitor launched deep learning jobs, and manage generated models.
It was part of YARN initially, and code resides under hadoop-yarn-applications. Later, the community decided to convert it to be a subproject within Hadoop (Sibling project of YARN, HDFS, etc.) because we want to support other resource management platforms like K8s. And finally, we're reconsidering Submarine's charter, and the Hadoop community voted that it is the time to moved Submarine to a separate Apache TLP.
Why Submarine?
ONE PLATFORM
Submarine is the ONE PLATFORM to allow Data Scientists to create end-to-end machine learning workflow. ONE PLATFORM means it supports Data Scientists and data engineers to finish their jobs on the same platform without frequently switching their toolsets. From dataset exploring data pipeline creation, model training, and tuning, and push model to production. All these steps can be completed within the ONE PLATFORM.
Resource Management Independent
It is also designed to be resource management independent, no matter if you have Apache Hadoop YARN, K8s, or just a container service, you will be able to run Submarine on top it.
Requirements and non-requirements
Notebook
1) Users should be able to create, edit, delete a notebook. (P0) 2) Notebooks can be persisted to storage and can be recovered if failure happens. (P0) 3) Users can trace back to history versions of a notebook. (P1) 4) Notebooks can be shared with different users. (P1) 5) Users can define a list of parameters of a notebook (looks like parameters of the notebook's main function) to allow executing a notebook like a job. (P1) 6) Different users can collaborate on the same notebook at the same time. (P2)
A running notebook instance is called notebook session (or session for short).
Experiment
Experiments of Submarine is an offline task. It could be a shell command, a Python command, a Spark job, a SQL query, or even a workflow.
The primary purposes of experiments under Submarine's context is to do training tasks, offline scoring, etc. However, experiment can be generalized to do other tasks as well.
Major requirement of experiment:
1) Experiments can be submitted from UI/CLI/SDK. 2) Experiments can be monitored/managed from UI/CLI/SDK. 3) Experiments should not bind to one resource management platform (K8s/YARN).
Type of experiments
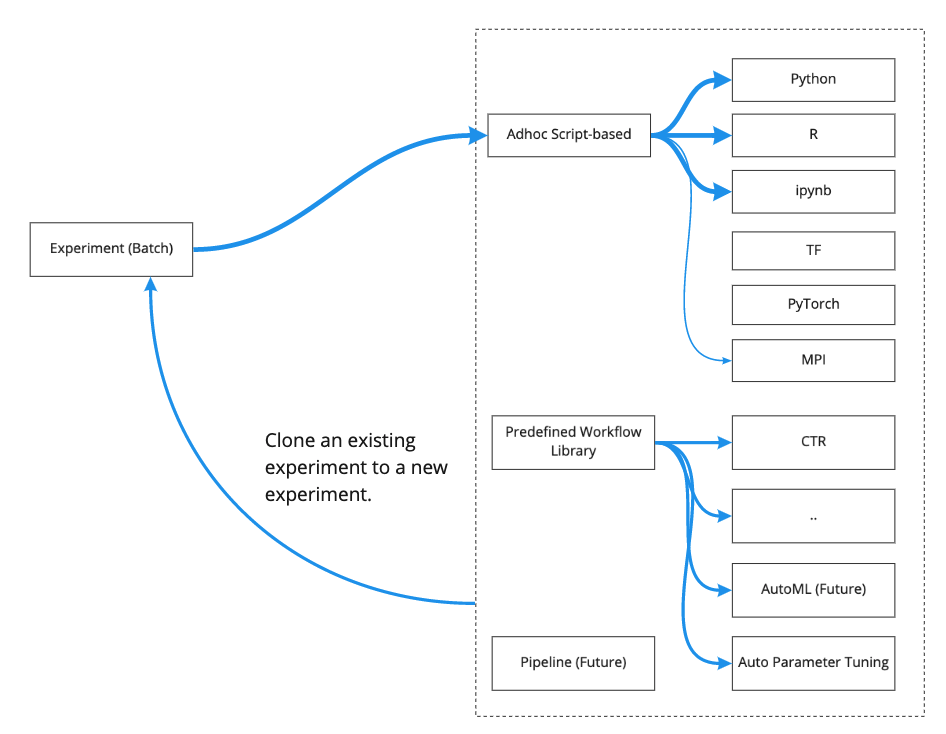
There're two types of experiments:
Adhoc experiments: which includes a Python/R/notebook, or even an adhoc Tensorflow/PyTorch task, etc.
Predefined experiment library: This is specialized experiments, which including developed libraries such as CTR, BERT, etc. Users are only required to specify a few parameters such as input, output, hyper parameters, etc. Instead of worrying about where's training script/dependencies located.
Adhoc experiment
Requirements:
- Allow run adhoc scripts.
- Allow model engineer, data scientist to run Tensorflow/Pytorch programs on YARN/K8s/Container-cloud.
- Allow jobs easy access data/models in HDFS/s3, etc.
- Support run distributed Tensorflow/Pytorch jobs with simple configs.
- Support run user-specified Docker images.
- Support specify GPU and other resources.
Predefined experiment library
Here's an example of predefined experiment library to train deepfm model:
{
"input": {
"train_data": ["hdfs:///user/submarine/data/tr.libsvm"],
"valid_data": ["hdfs:///user/submarine/data/va.libsvm"],
"test_data": ["hdfs:///user/submarine/data/te.libsvm"],
"type": "libsvm"
},
"output": {
"save_model_dir": "hdfs:///user/submarine/deepfm",
"metric": "auc"
},
"training": {
"batch_size" : 512,
"field_size": 39,
"num_epochs": 3,
"feature_size": 117581,
...
}
}
Predefined experiment libraries can be shared across users on the same platform, users can also add new or modified predefined experiment library via UI/REST API.
We will also model AutoML, auto hyper-parameter tuning to predefined experiment library.
Pipeline
Pipeline is a special kind of experiment:
- A pipeline is a DAG of experiments.
- Can be also treated as a special kind of experiment.
- Users can submit/terminate a pipeline.
- Pipeline can be created/submitted via UI/API.
Environment Profiles
Environment profiles (or environment for short) defines a set of libraries and when Docker is being used, a Docker image in order to run an experiment or a notebook.
Docker or VM image (such as AMI: Amazon Machine Images) defines the base layer of the environment.
On top of that, users can define a set of libraries (such as Python/R) to install.
Users can save different environment configs which can be also shared across the platform. Environment profiles can be used to run a notebook (e.g. by choosing different kernel from Jupyter), or an experiment. Predefined experiment library includes what environment to use so users don't have to choose which environment to use.
Environments can be added/listed/deleted/selected through CLI/SDK.
Model
Model management
- Model artifacts are generated by experiments or notebook.
- A model consists of artifacts from one or multiple files.
- Users can choose to save, tag, version a produced model.
- Once The Model is saved, Users can do the online model serving or offline scoring of the model.
Model serving
After model saved, users can specify a serving script, a model and create a web service to serve the model.
We call the web service to "endpoint". Users can manage (add/stop) model serving endpoints via CLI/API/UI.
Metrics for training job and model
Submarine-SDK provides tracking/metrics APIs, which allows developers to add tracking/metrics and view tracking/metrics from Submarine Workbench UI.
Deployment
Submarine Services (See architecture overview below) should be deployed easily on-prem / on-cloud. Since there're more and more public cloud offering for compute/storage management on cloud, we need to support deploy Submarine compute-related workloads (such as notebook session, experiments, etc.) to cloud-managed clusters.
This also include Submarine may need to take input parameters from customers and create/manage clusters if needed. It is also a common requirement to use hybrid of on-prem/on-cloud clusters.
Security / Access Control / User Management / Quota Management
There're 4 kinds of objects need access-control:
- Assets belong to Submarine system, which includes notebook, experiments and results, models, predefined experiment libraries, environment profiles.
- Data security. (Who owns what data, and what data can be accessed by each users).
- User credentials. (Such as LDAP).
- Other security, such as Git repo access, etc.
For the data security / user credentials / other security, it will be delegated to 3rd libraries such as Apache Ranger, IAM roles, etc.
Assets belong to Submarine system will be handled by Submarine itself.
Here're operations which Submarine admin can do for users / teams which can be used to access Submarine's assets.
Operations for admins
- Admin uses "User Management System" to onboard new users, upload user credentials, assign resource quotas, etc.
- Admins can create new users, new teams, update user/team mappings. Or remove users/teams.
- Admin can set resource quotas (if different from system default), permissions, upload/update necessary credentials (like Kerberos keytab) of a user.
- A DE/DS can also be an admin if the DE/DS has admin access. (Like a privileged user). This will be useful when a cluster is exclusively shared by a user or only shared by a small team.
Resource Quota Management Systemhelps admin to manage resources quotas of teams, organizations. Resources can be machine resources like CPU/Memory/Disk, etc. It can also include non-machine resources like $$-based budgets.
Dataset
There's also need to tag dataset which will be used for training and shared across the platform by different users.
Like mentioned above, access to the actual data will be handled by 3rd party system like Apache Ranger / Hive Metastore which is out of the Submarine's scope.
Architecture Overview
Architecture Diagram
+-----------------------------------------------------------------+
| Submarine UI / CLI / REST API / SDK |
| Mini-Submarine |
+-----------------------------------------------------------------+
+--------------------Submarine Server-----------------------------+
| +---------+ +---------+ +----------+ +----------+ +------------+|
| |Data set | |Notebooks| |Experiment| |Models | |Servings ||
| +---------+ +---------+ +----------+ +----------+ +------------+|
|-----------------------------------------------------------------|
| |
| +-----------------+ +-----------------+ +---------------------+ |
| |Experiment | |Compute Resource | |Other Management | |
| |Manager | | Manager | |Services | |
| +-----------------+ +-----------------+ +---------------------+ |
| Spark, template YARN/K8s/Docker |
| TF, PyTorch, pipeline |
| |
+ +-----------------+ +
| |Submarine Meta | |
| | Store | |
| +-----------------+ |
| |
+-----------------------------------------------------------------+
(You can use http://stable.ascii-flow.appspot.com/#Draw
to draw such diagrams)
Compute Resource Manager Helps to manage compute resources on-prem/on-cloud, this module can also handle cluster creation / management, etc.
Experiment Manager Work with "Compute Resource Manager" to submit different kinds of workloads such as (distributed) Tensorflow / Pytorch, etc.
Submarine SDK provides Java/Python/REST API to allow DS or other engineers to integrate into Submarine services. It also includes a mini-submarine component that launches Submarine components from a single Docker container (or a VM image).
Details of Submarine Server design can be found at submarine-server-design.